1. Introdução
Recentemente, enquanto trabalhava em um projeto, encontrei um problema de race condition. Esse problema específico, frequentemente visto em cenários de alta concorrência como e-commerce (ex: dois usuários tentando comprar o último item simultaneamente) ou sistemas de reserva (ex: reservas de propriedades sobrepostas), manifestou-se quando usuários tentaram adicionar dois registros simultaneamente, ignorando uma validação de check-before-insert.
Tais validações, projetadas para evitar duplicatas, podem falhar inesperadamente, especialmente quando uma aplicação opera em múltiplos pods ou containers paralelos. Quando encontrados pela primeira vez, a natureza inerente desses bugs pode ser sutil e confusa. Eles geralmente levam a sintomas como registros duplicados ou dados inconsistentes, e seu comportamento não determinístico sob carga pesada e concorrência os torna notoriamente difíceis de reproduzir e depurar.
Isso destaca por que entender race conditions é crítico em sistemas reais e por que implementar estratégias robustas para gerenciá-las efetivamente em ambientes de produção é primordial.
2. O que é uma Race Condition?
Uma race condition ocorre quando a correção de um programa depende do tempo ou do entrelaçamento de múltiplas operações concorrentes. Essencialmente, é uma falha onde a saída de um sistema é inesperadamente afetada pela sequência ou tempo de outros eventos incontroláveis. Isso geralmente acontece quando múltiplos processos ou threads acessam e modificam recursos compartilhados sem a sincronização adequada, levando a resultados imprevisíveis e, muitas vezes, incorretos.
3. Exemplo Simples
Para ilustrar o conceito central de uma race condition, particularmente o padrão ‘check-then-act’ prevalente em cenários como gerenciamento de inventário de e-commerce ou sistemas de reserva, considere um exemplo simplificado. Imagine um serviço projetado para garantir que um usuário tenha apenas uma entrada única em um banco de dados. Uma abordagem aparentemente lógica, porém falha, envolveria verificar a existência da entrada e, se ausente, prosseguir com a inserção:
public class UserService {
private Database database; // Suponha que esta seja uma interface de banco de dados simplificada
public void createUserEntry(String userId) {
if (!database.userEntryExists(userId)) {
// Simula algum tempo de processamento
try { Thread.sleep(100); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
database.insertUserEntry(userId);
System.out.println("Entrada de usuário para " + userId + " criada.");
} else {
System.out.println("Entrada de usuário para " + userId + " já existe.");
}
}
}
// Em um ambiente concorrente:
// Thread A chama createUserEntry("user1")
// Thread B chama createUserEntry("user1")
Em um ambiente concorrente, essa sequência ‘check-then-act’ torna-se problemática. Se a Thread A verificar userEntryExists e não encontrar nenhuma entrada, e a Thread B realizar a mesma verificação antes que a Thread A tenha completado sua operação insertUserEntry, ambas as threads concluirão erroneamente que nenhuma entrada existe. Consequentemente, ambas prosseguirão para inserir a entrada do usuário, levando a registros duplicados e violando o estado pretendido do sistema. Isso é análogo a dois clientes verificando simultaneamente o último produto disponível e ambos sendo informados de que está em estoque, apenas para que a compra de um falhe ou ocorra uma venda excessiva (oversell).
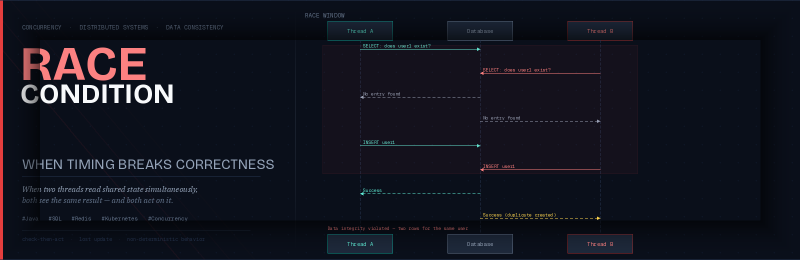
4. Seção de Visualização
sequenceDiagram
participant A as Thread A (Requisição 1)
participant B as Thread B (Requisição 2)
participant DB as Banco de Dados
A->>DB: SELECT: user1 existe?
B->>DB: SELECT: user1 existe?
DB-->>A: Nenhuma entrada encontrada
DB-->>B: Nenhuma entrada encontrada
Note over A,B: Ambas as threads acreditam que não existe entrada
A->>DB: INSERT user1
B->>DB: INSERT user1
DB-->>A: ✅ Sucesso
DB-->>B: ⚠️ Sucesso (duplicata criada)
Note over DB: Integridade de dados violada (sem constraint)
Este diagrama ilustra duas requisições concorrentes tentando criar uma entrada de usuário. Ambas as requisições leem o estado compartilhado (verificando se o usuário existe) aproximadamente ao mesmo tempo, não encontram nenhuma entrada existente e, em seguida, ambas prosseguem para escrever (inserir a entrada do usuário), levando a uma race condition.
5. Por que Race Conditions Acontecem
Race conditions são um subproduto comum de arquiteturas de software modernas, principalmente devido a:
- Concorrência: A execução simultânea de múltiplas threads, processos ou serviços distribuídos que compartilham recursos. Isso é inerente a aplicações multi-threaded, servidores web lidando com múltiplas requisições e arquiteturas de microserviços.
- Falta de Sincronização: Quando o acesso a recursos compartilhados (como registros de banco de dados, caches em memória ou arquivos) não é devidamente coordenado, permitindo que múltiplas operações interfiram umas nas outras.
- Suposição Incorreta de Atomicidade: Desenvolvedores às vezes assumem que uma sequência de operações (ex: read-modify-write) será executada como uma unidade única e indivisível, quando na realidade, elas podem ser interrompidas e entrelaçadas por outras operações.
Sistemas modernos, especialmente aqueles construídos com APIs e microserviços, aumentam significativamente a exposição a race conditions devido à sua natureza distribuída e altamente concorrente.
6. Tipos de Race Conditions
Race conditions manifestam-se de várias formas, mas as mais críticas frequentemente envolvem um padrão ‘check-then-act’, onde uma decisão é tomada com base em um estado percebido que pode mudar antes que a ação seja concluída. Dois tipos comuns e impactantes são:
6.1 Check-Then-Act Race Condition (ex: Inserções Duplicadas, Venda Excessiva de Inventário, Reservas Sobrepostas)
Este tipo de race condition é precisamente o que discutimos no exemplo simples. Ocorre quando múltiplas operações concorrentes realizam uma verificação (ex: “este produto está em estoque?” ou “este horário está disponível?”) e, com base nessa verificação, prosseguem para agir (ex: “decrementar estoque” ou “reservar horário”). Se o estado mudar entre a verificação e a ação devido a outra operação concorrente, o sistema pode acabar em um estado inconsistente. Isso leva a problemas como registros duplicados, venda excessiva de inventário ou reserva dupla de recursos, que podem ter implicações comerciais significativas.
6.2 Update Race Condition (Lost Update)
Uma update race condition, frequentemente referida como lost update, ocorre quando duas ou mais operações concorrentes tentam modificar o mesmo dado, e uma atualização sobrescreve outra sem incorporar suas alterações. Por exemplo, se dois usuários tentarem atualizar simultaneamente a quantidade de um item em um sistema de inventário, e ambos lerem a quantidade atual, realizarem um cálculo e, em seguida, escreverem a nova quantidade, uma das atualizações será perdida. Embora ainda seja uma preocupação, estas são frequentemente tratadas de forma diferente com mecanismos de bloqueio padrão em comparação com os cenários ‘check-then-act’, onde a própria verificação inicial é vulnerável.
7. Estratégias para Resolver Race Conditions
Não existe uma solução única e universal para todas as race conditions. A melhor abordagem depende do contexto específico, do tipo de recurso compartilhado e dos requisitos de desempenho. Aqui estão várias estratégias eficazes:
7.1 Database Constraints
Para prevenir race conditions de inserção e garantir a integridade dos dados, as unique constraints do banco de dados são frequentemente a única garantia confiável de correção sob escritas concorrentes. Ao definir uma unique constraint em uma ou mais colunas, o próprio banco de dados impõe a integridade dos dados no nível mais fundamental. Se uma inserção concorrente tentar criar uma duplicata, o banco de dados lançará um erro, que a aplicação poderá tratar graciosamente. É um princípio crítico a ser lembrado: Verificações em nível de aplicação não são garantias sob concorrência.
ALTER TABLE user_entries ADD CONSTRAINT unique_user_id UNIQUE (user_id);
Esta abordagem transfere a responsabilidade da correção para o banco de dados, que é altamente otimizado para tais tarefas. É uma verdade fundamental no design de sistemas concorrentes: Na maioria dos sistemas, o banco de dados é a única camada que pode garantir de forma confiável a consistência sob escritas concorrentes — todo o resto é o melhor esforço (best-effort).
7.2 Transactions + Locks (Check-Then-Insert com Locking)
Para cenários onde as constraints do banco de dados sozinhas são insuficientes, ou para operações de read-modify-write mais complexas, transações de banco de dados combinadas com bloqueio explícito podem ser usadas. É crucial entender que o SELECT FOR UPDATE bloqueia apenas linhas existentes. Esta abordagem NÃO evita race conditions de inserção quando a linha ainda não existe; uma unique constraint ainda é necessária. O SELECT FOR UPDATE é eficaz para bloquear linhas que se espera que existam e sejam modificadas. Por exemplo, em bancos de dados SQL, o SELECT FOR UPDATE pode ser usado para adquirir um bloqueio exclusivo em uma linha (ou linhas) existente antes de realizar uma atualização, garantindo que nenhuma outra transação possa modificar ou bloquear essa linha até que a transação atual seja confirmada ou revertida.
-- Transação 1: Bloqueando uma linha existente para atualização
BEGIN;
SELECT * FROM products WHERE id = 123 FOR UPDATE;
UPDATE products SET quantity = quantity - 1 WHERE id = 123;
COMMIT;
-- Transação 2 (aguardará a Transação 1 confirmar ou reverter se tentar adquirir o mesmo bloqueio no produto id 123)
Isso garante que apenas uma transação possa operar nos dados bloqueados por vez, fornecendo exclusão mútua e prevenindo race conditions em registros existentes. É importante notar que, embora as transações forneçam atomicidade (tudo ou nada), os bloqueios (ex: SELECT FOR UPDATE) fornecem exclusão mútua e coordenação. Níveis de isolamento adequados e/ou mecanismos de bloqueio explícitos são necessários para alcançar o controle total de concorrência e evitar race conditions.
7.2.1 Níveis de Isolamento de Transação
Os níveis de isolamento de transação do banco de dados desempenham um papel crítico em como as race conditions são tratadas. O isolamento READ COMMITTED, o padrão para muitos bancos de dados, não evita race conditions como lost updates ou leituras não repetíveis. O REPEATABLE READ oferece garantias mais fortes, evitando leituras não repetíveis, mas ainda permitindo race conditions de inserção (phantom reads) conforme definido pelo padrão SQL. O nível de isolamento mais alto, SERIALIZABLE, evita efetivamente todas as race conditions ao garantir que as transações sejam executadas como se fossem rodadas sequencialmente, mas isso vem com um impacto significativo no desempenho devido ao aumento de bloqueios e contenção.
Nota: A implementação de
REPEATABLE READdo PostgreSQL é mais forte do que o padrão SQL exige. Como utiliza snapshot isolation em vez de bloqueios de intervalo (range locks), ele também evita phantom reads na prática — comportamento que o padrão só garante emSERIALIZABLE. Se você estiver trabalhando exclusivamente com PostgreSQL, oREPEATABLE READpode ser suficiente para cenários onde outros bancos de dados exigiriamSERIALIZABLE.
7.3 UPSERT (INSERT … ON CONFLICT / ON DUPLICATE KEY)
UPSERT (uma aglutinação de “UPDATE” e “INSERT”) é uma solução comum e altamente eficaz no mundo real para evitar inserções duplicadas e lidar com atualizações concorrentes, especialmente quando uma unique constraint está presente. Esse padrão permite que uma aplicação tente uma inserção e, se surgir um conflito devido a uma chave única existente, ela pode não fazer nada ou atualizar a linha existente. Isso depende diretamente da capacidade do banco de dados de lidar com o conflito de forma atômica, tornando-o mais simples e seguro do que a lógica de check-then-act em nível de aplicação.
Exemplo PostgreSQL:
INSERT INTO user_entries (user_id)
VALUES ('user1')
ON CONFLICT (user_id) DO NOTHING;
Exemplo MySQL:
INSERT INTO user_entries (user_id)
VALUES ('user1')
ON DUPLICATE KEY UPDATE user_id = user_id;
Operações de UPSERT são inerentemente idempotentes quando combinadas com uma unique constraint, pois garantem que execuções repetidas levem ao mesmo estado final. Esse padrão é frequentemente a forma preferida de lidar com cenários de ‘check-then-act’ para inserções quando uma unique constraint é definida.
7.4 Pessimistic Locking
O pessimistic locking assume que conflitos são prováveis e os evita adquirindo um bloqueio em um recurso antes de acessá-lo. Isso significa que outras operações que tentarem acessar o mesmo recurso serão bloqueadas até que o bloqueio seja liberado. Embora eficaz na prevenção de race conditions, pode levar à redução da concorrência e a potenciais deadlocks se não for gerenciado com cuidado.
- Prós: Garante a consistência dos dados, relativamente simples de implementar para seções críticas.
- Contras: Pode reduzir significativamente o throughput do sistema, aumenta o risco de deadlocks e pode ser complexo de gerenciar em sistemas distribuídos. Para mitigar deadlocks, sempre adquira bloqueios em uma ordem consistente entre as transações e utilize timeouts de bloqueio para evitar o bloqueio indefinido.
7.5 Optimistic Locking
Em contraste com o pessimistic locking, o optimistic locking assume que os conflitos são raros. Em vez de bloquear recursos antecipadamente, ele permite que múltiplas operações prossigam concorrentemente. Quando uma operação tenta confirmar suas alterações, ela verifica se o recurso foi modificado por outra operação concorrente desde que foi lido inicialmente. Isso é normalmente alcançado usando um número de versão ou uma coluna de timestamp. Crucialmente, essa verificação de versão deve, idealmente, ser imposta no nível do banco de dados para fornecer uma garantia real.
Este padrão frequentemente envolve uma atualização condicional no nível do banco de dados:
UPDATE product
SET quantity = ?, version = version + 1
WHERE id = ? AND version = ?;
Após executar tal instrução UPDATE, a aplicação verifica o número de linhas afetadas. Se exatamente uma linha foi afetada, a atualização foi bem-sucedida. Se zero linhas foram afetadas, isso indica que outra transação modificou o registro concorrentemente (ou seja, a version na cláusula WHERE não correspondia mais) e um conflito foi detectado. Nesse caso, a operação é normalmente revertida e o cliente é instruído a tentar novamente. Essa abordagem oferece maior concorrência, mas requer a implementação de lógica de tentativa (retry) no lado do cliente.
- Prós: Alta concorrência, evita deadlocks.
- Contras: Requer mecanismos de tentativa, conflitos podem levar a trabalho desperdiçado se as tentativas forem frequentes.
7.6 Idempotency Keys
Idempotency keys são um mecanismo poderoso, particularmente útil no design de APIs e sistemas distribuídos, principalmente para evitar o processamento duplicado de requisições (ex: devido a tentativas no lado do cliente ou problemas de rede). Uma operação idempotente é aquela que pode ser aplicada múltiplas vezes sem alterar o resultado além da aplicação inicial. Ao incluir uma idempotency key única em cada requisição, o servidor pode detectar e ignorar requisições subsequentes com a mesma chave, garantindo que uma operação (ex: cobrar um cliente, criar um recurso) seja realizada apenas uma vez. As idempotency keys são normalmente impostas usando uma unique constraint no nível do banco de dados. É crucial entender que, embora as idempotency keys evitem que requisições duplicadas causem efeitos duplicados, elas não substituem inerentemente os mecanismos adequados de controle de concorrência para gerenciar o estado compartilhado. Elas abordam o problema da entrega de mensagens duplicadas, não o acesso concorrente a um recurso compartilhado.
7.7 Distributed Locks (Avançado)
Em sistemas distribuídos, onde múltiplos serviços ou instâncias podem estar tentando acessar o mesmo recurso compartilhado, os bloqueios tradicionais em processo são insuficientes. Distributed locks são usados para coordenar o acesso entre diferentes processos ou máquinas. Ferramentas como Redis ou Apache ZooKeeper podem ser usadas para implementar mecanismos de bloqueio distribuído.
Para instâncias simples de Redis de nó único, um bloqueio distribuído básico pode ser implementado usando o comando SET key value NX PX milliseconds. Este comando define uma chave apenas se ela ainda não existir (NX) e define um tempo de expiração (PX), fornecendo um mecanismo básico de exclusão mútua. No entanto, essa abordagem é vulnerável se a instância do Redis falhar.
Para implantações de Redis com múltiplos nós (ex: Redis Sentinel ou Cluster), algoritmos como Redlock foram propostos para alcançar bloqueios distribuídos mais robustos. No entanto, é crucial notar que bloqueios distribuídos baseados em Redis, como o Redlock, são controversos e devem ser usados com extrema cautela. Bloqueios distribuídos nunca devem ser a única linha de defesa para a consistência dos dados; a correção ainda deve ser garantida no nível do banco de dados. Eles introduzem uma complexidade significativa e suas garantias de correção sob vários cenários de falha são debatidas na comunidade de engenharia [1][2]. Implementar bloqueios distribuídos é significativamente mais complexo e introduz seu próprio conjunto de desafios, incluindo latência de rede, tolerância a falhas e garantia de consistência.
- Aviso: Bloqueios distribuídos adicionam complexidade significativa e só devem ser considerados quando soluções mais simples não forem viáveis para ambientes distribuídos. Seja particularmente cauteloso com soluções como Redlock sem uma compreensão profunda de suas limitações e trade-offs.
8. Escolhendo a Abordagem Correta
Selecionar a estratégia apropriada para lidar com race conditions envolve entender os trade-offs entre consistência, desempenho e complexidade.
Uma boa regra prática é: sempre que possível, empurre as garantias de correção para a camada do banco de dados em vez de depender da coordenação em nível de aplicação.
- Race Conditions de Check-Then-Act (ex: Inserções Duplicadas, Venda Excessiva, Reservas Sobrepostas): Para esses cenários críticos, as unique constraints do banco de dados são a solução primária e mais confiável para evitar inserções duplicadas. Ao lidar com mudanças de estado complexas ou alocação de recursos, mecanismos robustos como transações com
SELECT FOR UPDATE(pessimistic locking) ou distributed locks cuidadosamente implementados são frequentemente necessários para garantir a atomicidade e evitar race conditions. A escolha aqui depende dos requisitos específicos de consistência, da natureza do recurso compartilhado e dos trade-offs aceitáveis em desempenho e complexidade. - Race Conditions de Atualização (Lost Updates): Para evitar atualizações perdidas, o optimistic locking é geralmente a abordagem preferida devido à sua maior concorrência, especialmente em aplicações web onde múltiplos usuários podem editar dados simultaneamente. Ele lida efetivamente com conflitos exigindo lógica de tentativa no lado do cliente.
- Seções Críticas (exigindo exclusão mútua estrita): Quando a consistência absoluta dos dados é primordial para uma seção crítica curta e bem definida, o pessimistic locking (ex:
SELECT FOR UPDATEem registros existentes) pode ser empregado. No entanto, deve-se estar agudamente ciente de seu impacto no throughput do sistema e do risco aumentado de deadlocks.
Sempre considere os requisitos específicos do seu sistema e o impacto potencial de cada solução no desempenho e na manutenibilidade.
9. Lições Aprendidas (Insight Pessoal)
Meus encontros com race conditions me ensinaram várias lições inestimáveis:
- Race conditions são sutis e difíceis de reproduzir: Elas frequentemente se manifestam sob condições de carga específicas ou sequências de tempo raras, tornando-as notoriamente difíceis de depurar em ambientes de desenvolvimento.
- Se a correção depende do tempo, seu sistema está contando com a sorte. Qualquer código que dependa da ordem precisa ou da velocidade de execução de operações concorrentes é um candidato principal para uma race condition. Sempre questione as suposições sobre o tempo.
- Prefira garantias em vez de suposições: Em vez de assumir que as operações são atômicas ou que fatores externos sempre se alinharão, construa sistemas que forneçam garantias explícitas de correção, seja por meio de constraints de banco de dados, mecanismos de bloqueio ou operações idempotentes.
- Evite depender de uma única camada para validação (quando possível): Quando o seu sistema utiliza garantias fortes em uma camada inferior (como database constraints), muitas vezes é vantajoso complementá-las com validação na aplicação (por exemplo, um check-before-insert). Essa verificação adicional não garante correção sob concorrência, mas pode reduzir operações desnecessárias no banco de dados e, mais importante, melhorar a experiência do usuário ao falhar mais rapidamente e fornecer feedback mais claro. Na prática, a camada inferior garante a correção, enquanto a camada de aplicação otimiza a usabilidade e a eficiência.
10. Conclusão
Race conditions são um desafio inerente em sistemas concorrentes e distribuídos. Embora possam ser elusivas e frustrantes de depurar, entender suas causas e conhecer as várias estratégias para mitigá-las é crucial para construir software robusto e confiável. Ao impor a correção na camada correta — frequentemente o banco de dados — e escolher cuidadosamente os mecanismos de sincronização, os engenheiros de software podem lidar efetivamente com race conditions e garantir a integridade de seus sistemas.
11. Opcional: Testando Race Conditions
Testar para race conditions é inerentemente difícil devido à sua natureza não determinística. No entanto, várias estratégias podem ajudar a descobri-las:
- Requisições Paralelas: Simule múltiplas requisições concorrentes para o mesmo endpoint ou recurso. Ferramentas como Apache JMeter ou scripts personalizados podem ser usados para inundar o sistema com operações simultâneas.
- Testes de Carga: Sujeitar o sistema a uma carga alta pode aumentar a probabilidade de race conditions se manifestarem. Isso ajuda a identificar gargalos e áreas onde problemas de concorrência podem surgir.
- Chaos Engineering: Introduzir intencionalmente latência ou falhas em um ambiente controlado pode, às vezes, expor bugs dependentes do tempo que levam a race conditions.
Embora desafiador, incorporar essas estratégias de teste em seu fluxo de trabalho de desenvolvimento pode melhorar significativamente a resiliência de suas aplicações contra race conditions.
12. Referências
[1] Kleppmann, M. (2016, 8 de fevereiro). How to do distributed locking. https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
[2] Antirez. (2016, 9 de fevereiro). Is Redlock safe? https://antirez.com/news/101