Na busca por construir sistemas de software robustos, manuteníveis e testáveis, os princípios arquiteturais desempenham um papel fundamental. Entre eles, o Princípio da Inversão de Dependência (DIP) se destaca como um pilar para alcançar designs altamente desacoplados e flexíveis, especialmente quando aplicado dentro de frameworks como a Clean Architecture. Este post explorará o Princípio da Inversão de Dependência, esclarecerá sua relação com a Injeção de Dependência e demonstrará sua aplicação prática em Java, com foco no desacoplamento entre as camadas de Domínio e Infraestrutura.
Entendendo o Princípio da Inversão de Dependência (DIP)
O Princípio da Inversão de Dependência, um dos cinco princípios SOLID do design orientado a objetos, foi articulado por Robert C. Martin (Uncle Bob). Ele consiste em duas afirmações centrais [1]:
- Módulos de alto nível não devem depender de módulos de baixo nível. Ambos devem depender de abstrações.
- Abstrações não devem depender de detalhes. Detalhes devem depender de abstrações.
Em essência, o DIP defende que o software seja projetado de forma que os módulos dependam de abstrações (interfaces ou classes abstratas) em vez de implementações concretas. Esse princípio garante que as políticas de alto nível e a lógica de negócio permaneçam independentes dos detalhes de implementação de baixo nível. Essa inversão na direção da dependência é fundamental para a criação de sistemas de software flexíveis e resilientes.
DIP vs. Injeção de Dependência (DI)
É comum confundir o DIP com a Injeção de Dependência (DI), mas são conceitos distintos:
- Princípio da Inversão de Dependência (DIP) é um princípio de design. Trata-se da direção das dependências, afirmando que módulos de alto nível não devem depender de módulos de baixo nível, mas sim de abstrações. É uma diretriz arquitetural de alto nível, focada no que alcançar em termos de direção de dependência [2].
- Injeção de Dependência (DI) é um padrão de design e uma técnica para implementar o DIP. Trata-se de como as dependências são fornecidas a uma classe. Em vez de a própria classe criar suas dependências, elas são injetadas nela a partir de uma fonte externa (geralmente um container de DI). A DI é um mecanismo concreto para como alcançar a inversão de controle prescrita pelo DIP [3].
Em termos mais simples, o DIP é a estratégia para o desacoplamento, e a DI é uma das táticas para executar essa estratégia.
O Princípio da Inversão de Dependência na Clean Architecture
graph TD
subgraph DomainLayer ["🏛️ Camada de Domínio"]
direction TB
U["👤 User<br/>Entidade"]
URI["📋 UserRepository<br/>«interface»"]
end
subgraph ApplicationLayer ["🎯 Camada de Aplicação"]
direction TB
UC["🔧 CreateUserUseCase<br/><span style="white-space: nowrap;">Orquestra objetos de domínio</span>"]
end
subgraph InfrastructureLayer ["<span style="white-space: nowrap;">🔌 Camada de Infraestrutura</sp>"]
direction TB
URA["<span style="white-space: nowrap;">🗄️ JpaUserRepositoryAdapter</span><br/>implementa UserRepository"]
DB[("💾 Banco de Dados<br/>PostgreSQL / MySQL")]
end
subgraph CompositionRoot ["🧩 Composition Root"]
direction TB
DI["⚡ Container de DI<br/>Spring / Guice / Manual"]
end
%% Setas de dependência principais
UC -->|"<span style="white-space: nowrap;">depende de (tempo de compilação)</span>"| URI
URA -.->|"<span style="white-space: nowrap;">implementa (ligação em runtime)</span>"| URI
%% Relações internas do domínio
UC -->|usa| U
URA -->|mapeia de/para| U
URA -->|persiste via| DB
%% Container de DI conecta o adapter ao use case
DI -->|"injeta adapter no use case"| UC
%% Estilização — paleta refinada
classDef domain fill:#1e1b4b,color:#e0e7ff,stroke:#6366f1,stroke-width:2px
classDef application fill:#14532d,color:#dcfce7,stroke:#22c55e,stroke-width:2px
classDef infra fill:#1c1917,color:#fef3c7,stroke:#f59e0b,stroke-width:2px
classDef composition fill:#1e293b,color:#e2e8f0,stroke:#94a3b8,stroke-width:2px,stroke-dasharray:6 3
class U,URI domain
class UC application
class URA,DB infra
class DI composition
style DomainLayer fill:#0f0e2a,color:#a5b4fc,stroke:#6366f1,stroke-width:3px
style ApplicationLayer fill:#052e16,color:#86efac,stroke:#22c55e,stroke-width:3px
style InfrastructureLayer fill:#0c0a09,color:#fde68a,stroke:#f59e0b,stroke-width:3px
style CompositionRoot fill:#0f172a,color:#cbd5e1,stroke:#64748b,stroke-width:2px,stroke-dasharray:8 4
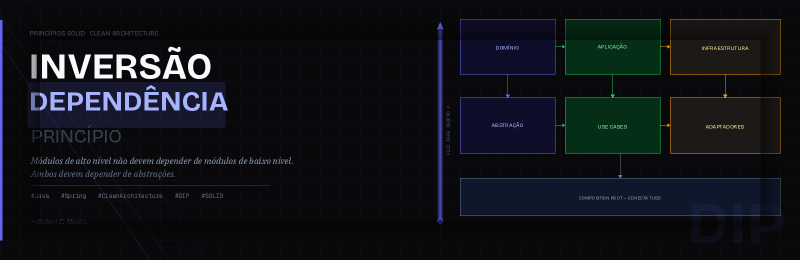
A Clean Architecture, defendida por Robert C. Martin, estrutura as aplicações em camadas concêntricas, com a lógica de negócio central (a camada de Domínio) no centro. Uma regra fundamental da Clean Architecture é a Regra da Dependência: as dependências do código-fonte devem sempre apontar para dentro, em direção às políticas e regras de negócio de mais alto nível. Nenhuma camada externa deve jamais afetar uma camada interna [2].
É exatamente aqui que o DIP se torna indispensável. Sem o DIP, a Camada de Aplicação (que contém os Use Cases, representando as políticas de alto nível) dependeria naturalmente da Camada de Infraestrutura (detalhes de baixo nível) para coisas como acesso ao banco de dados ou chamadas a serviços externos. Por exemplo, um CreateUserUseCase poderia chamar diretamente um JpaUserRepository.
O DIP resolve isso invertendo a dependência. Em vez de a Camada de Aplicação depender da Camada de Infraestrutura, ambas as camadas dependem de uma abstração definida dentro da própria Camada de Domínio. A Camada de Infraestrutura então implementa essa abstração.
Considere o fluxo típico:
- Camada de Aplicação (ex.: Use Cases) depende de interfaces (abstrações) definidas na Camada de Domínio.
- Camada de Domínio define as entidades de negócio centrais, value objects, domain services e interfaces (abstrações) para preocupações externas, como persistência de dados.
- Camada de Infraestrutura (ex.: repositórios concretos) implementa essas interfaces definidas na Camada de Domínio.
- Em tempo de execução, um mecanismo externo (geralmente um framework de Injeção de Dependência) fornece à Camada de Aplicação instâncias das implementações da Camada de Infraestrutura, mas apenas por meio de suas interfaces abstratas.
Isso significa que a dependência do código-fonte flui da Camada de Infraestrutura em direção à Camada de Domínio (porque a Infraestrutura implementa uma interface definida no Domínio), enquanto a Camada de Aplicação depende da Camada de Domínio. O fluxo de controle (em tempo de execução) vai da Camada de Aplicação, passando pelas abstrações da Camada de Domínio, até as implementações da Camada de Infraestrutura. Essa inversão é fundamental para manter a independência da lógica de negócio central e dos use cases.
Exemplo Prático em Java
Vamos ilustrar como o DIP é aplicado em uma aplicação Java seguindo os princípios da Clean Architecture, utilizando uma entidade User, um UserRepository para persistência de dados e um CreateUserUseCase.
1. Camada de Domínio: Definindo a Abstração (Lógica de Negócio Central)
A camada de Domínio contém a lógica de negócio central, definindo a entidade User e a interface UserRepository. Essa interface é a abstração da qual o CreateUserUseCase (na Camada de Aplicação) dependerá. Ao colocar a interface aqui, a camada de Domínio permanece completamente desconhecida de como os dados do usuário são de fato persistidos.
// domain/model/User.java
package com.example.cleanarch.domain.model;
public class User {
private String id;
private String name;
private String email;
public User(String id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
// Getters e setters
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
}
// domain/port/UserRepository.java (Abstração/Port)
package com.example.cleanarch.domain.port;
import com.example.cleanarch.domain.model.User;
import java.util.Optional;
public interface UserRepository {
User save(User user);
Optional<User> findById(String id);
}
2. Camada de Aplicação: Definindo os Use Cases (Política de Alto Nível)
A camada de Aplicação contém as regras de negócio específicas da aplicação e orquestra o fluxo de dados de e para a camada de Domínio. Aqui, o CreateUserUseCase depende da interface UserRepository definida na camada de Domínio.
// application/usecase/CreateUserUseCase.java (Módulo de Alto Nível)
package com.example.cleanarch.application.usecase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
public class CreateUserUseCase {
private final UserRepository userRepository;
public CreateUserUseCase(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User execute(User user) {
// Lógica de negócio específica da aplicação pode ser inserida aqui antes de salvar
// ex.: validação, logging, publicação de eventos
return userRepository.save(user);
}
}
3. Camada de Infraestrutura: Implementando a Abstração (Detalhe de Baixo Nível)
A camada de Infraestrutura contém os detalhes concretos, como o acesso ao banco de dados. Aqui, implementamos a interface UserRepository definida na camada de Domínio. Essa implementação pode usar um framework específico de banco de dados como Spring Data JPA, Hibernate ou um cliente NoSQL.
// infrastructure/adapter/JpaUserRepositoryAdapter.java (Detalhe/Adapter)
package com.example.cleanarch.infrastructure.adapter;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository // Exemplo com Spring Framework
public class JpaUserRepositoryAdapter implements UserRepository {
// Assume um repositório Spring Data JPA para as operações reais no BD
private final SpringDataJpaUserRepository springDataJpaUserRepository;
public JpaUserRepositoryAdapter(SpringDataJpaUserRepository springDataJpaUserRepository) {
this.springDataJpaUserRepository = springDataJpaUserRepository;
}
@Override
public User save(User user) {
// Converte o User do domínio para entidade JPA se necessário
// Salva usando springDataJpaUserRepository
System.out.println("Salvando usuário no banco de dados: " + user.getName());
return user; // Por simplicidade, retornando o mesmo usuário
}
@Override
public Optional<User> findById(String id) {
// Busca usando springDataJpaUserRepository e converte para User do domínio
System.out.println("Buscando usuário por ID: " + id);
return Optional.of(new User(id, "Usuário Teste", "teste@exemplo.com")); // Mock por simplicidade
}
}
// Repositório Spring Data JPA fictício (estaria em infrastructure/repository)
interface SpringDataJpaUserRepository {
// UserEntity save(UserEntity userEntity);
// Optional<UserEntity> findById(String id);
}
Observe que JpaUserRepositoryAdapter depende de UserRepository (uma abstração na camada de Domínio). Essa é a inversão: o módulo de baixo nível agora depende da abstração de alto nível, e não o contrário.
4. Composition Root: Conectando as Dependências
No Composition Root (um módulo de configuração dedicado que fica fora das camadas centrais, embora em aplicações Spring geralmente resida em um pacote application/config), o JpaUserRepositoryAdapter concreto é fornecido ao CreateUserUseCase. Isso é feito tipicamente usando um framework de Injeção de Dependência (como Spring, Guice ou Dagger), que automatiza o processo de criação de instâncias e as injeta por meio da interface UserRepository.
// application/config/AppConfig.java (Exemplo de Composition Root com Spring)
package com.example.cleanarch.application.config;
import com.example.cleanarch.application.usecase.CreateUserUseCase;
import com.example.cleanarch.domain.port.UserRepository;
import com.example.cleanarch.infrastructure.adapter.JpaUserRepositoryAdapter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public UserRepository userRepository() {
// Em uma aplicação real, isso envolveria criar e configurar
// o SpringDataJpaUserRepository real ou similar.
// Para este exemplo, passaremos null por simplicidade.
return new JpaUserRepositoryAdapter(null); // O repositório Spring Data JPA real seria injetado aqui pelo Spring
}
@Bean
public CreateUserUseCase createUserUseCase(UserRepository userRepository) {
return new CreateUserUseCase(userRepository);
}
// Exemplo de como usar (ex.: em um método main ou controller)
public static void main(String[] args) {
// Esta parte é tipicamente tratada pelo Spring Application Context
// Para demonstração:
UserRepository repo = new JpaUserRepositoryAdapter(null);
CreateUserUseCase useCase = new CreateUserUseCase(repo);
User newUser = new User("1", "João Silva", "joao.silva@exemplo.com");
useCase.execute(newUser);
}
}
Em tempo de execução, o CreateUserUseCase recebe uma instância de JpaUserRepositoryAdapter por meio de sua interface UserRepository. As camadas de Aplicação e Domínio permanecem alheias à implementação concreta, aderindo estritamente ao DIP.
Conexão Manual (Sem Framework)
Vale a pena entender o que um framework de DI faz por baixo dos panos. Aqui está a conexão equivalente feita inteiramente à mão — sem Spring, sem Guice, apenas Java puro:
// main/Main.java (Composition Root Manual)
package com.example.cleanarch.main;
import com.example.cleanarch.application.usecase.CreateUserUseCase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import com.example.cleanarch.infrastructure.adapter.JpaUserRepositoryAdapter;
public class Main {
public static void main(String[] args) {
// 1. Criar o detalhe de baixo nível (o adapter concreto)
UserRepository repository = new JpaUserRepositoryAdapter(null);
// 2. Injetá-lo no use case de alto nível por meio da interface
CreateUserUseCase createUser = new CreateUserUseCase(repository);
// 3. Executar — CreateUserUseCase não tem ideia de que está falando com JPA
User newUser = new User("1", "João Silva", "joao.silva@exemplo.com");
createUser.execute(newUser);
}
}
Essa é a essência do DIP em ação. CreateUserUseCase é construído com uma referência UserRepository e jamais sabe — nem se importa — que o tipo concreto por trás dela é JpaUserRepositoryAdapter. Um framework como o Spring simplesmente automatiza essa conexão em larga escala, varrendo anotações @Bean ou @Component e construindo todo o grafo de objetos para você. O princípio é idêntico; o framework apenas remove o boilerplate.
Testando com DIP: Substituindo o Repositório
Um dos benefícios mais imediatos e tangíveis do DIP é como ele simplifica drasticamente os testes unitários. Como CreateUserUseCase depende da interface UserRepository em vez de uma classe JPA concreta, você pode substituí-la por um mock leve em memória durante os testes — sem banco de dados, sem contexto Spring, sem I/O lento.
// application/usecase/CreateUserUseCaseTest.java
package com.example.cleanarch.application.usecase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import static org.junit.jupiter.api.Assertions.*;
class CreateUserUseCaseTest {
// Um stub simples em memória — sem Mockito, sem Spring, sem banco de dados
static class InMemoryUserRepository implements UserRepository {
private final List<User> store = new ArrayList<>();
@Override
public User save(User user) {
store.add(user);
return user;
}
@Override
public Optional<User> findById(String id) {
return store.stream().filter(u -> u.getId().equals(id)).findFirst();
}
public List<User> getStore() { return store; }
}
@Test
void shouldSaveUserSuccessfully() {
// Arrange: injeta o stub em memória por meio da interface
InMemoryUserRepository fakeRepo = new InMemoryUserRepository();
CreateUserUseCase useCase = new CreateUserUseCase(fakeRepo);
User user = new User("1", "João Silva", "joao.silva@exemplo.com");
// Act
User result = useCase.execute(user);
// Assert: lógica de negócio verificada, zero infraestrutura envolvida
assertNotNull(result);
assertEquals("João Silva", result.getName());
assertEquals(1, fakeRepo.getStore().size());
}
}
Como a abstração UserRepository reside na camada de Domínio, o teste não importa nada da camada de Infraestrutura. Trocar JpaUserRepositoryAdapter por InMemoryUserRepository é trivial — basta passar uma implementação diferente ao construtor. Esse é o benefício do DIP: sua lógica de negócio é totalmente testável em isolamento, sem necessidade de um banco de dados em execução ou um contexto Spring carregado.
Benefícios do Princípio da Inversão de Dependência
Aplicar o DIP, especialmente dentro da Clean Architecture, traz inúmeras vantagens:
- Desacoplamento Aprimorado: Módulos de alto nível (Use Cases da Camada de Aplicação) são completamente independentes dos detalhes de implementação de baixo nível (Camada de Infraestrutura). Isso significa que mudanças na tecnologia de banco de dados ou em serviços externos não exigem alterações na lógica de negócio central ou nos fluxos da aplicação.
- Testabilidade Melhorada: Como os módulos de alto nível dependem de abstrações definidas na Camada de Domínio, é simples fornecer implementações mock ou stub dessas abstrações durante os testes unitários. Isso permite o teste isolado da lógica de negócio e dos use cases sem dependências externas.
- Maior Flexibilidade e Manutenibilidade: O sistema se torna mais adaptável a mudanças. Novas implementações de uma abstração podem ser introduzidas sem alterar os módulos de alto nível. Isso simplifica a manutenção e permite uma evolução mais fácil do sistema.
- Promove a Reusabilidade: A lógica de negócio central e os use cases da aplicação, livres de preocupações com infraestrutura, podem ser reutilizados em diferentes aplicações ou contextos de implantação.
- Arquitetura Mais Clara: O DIP impõe fronteiras claras entre as camadas, tornando a arquitetura mais fácil de entender e raciocinar.
Trade-offs do Mundo Real: Quando o DIP Brilha e Quando Não
O DIP é uma ferramenta poderosa, mas como qualquer princípio de design, aplicá-lo indiscriminadamente pode introduzir complexidade desnecessária. Entender onde ele agrega mais valor — e onde pode ser excessivo — é fundamental para usá-lo com sabedoria.
Quando o DIP é mais valioso é precisamente nas fronteiras entre sua lógica de negócio central e preocupações externas voláteis: bancos de dados, message brokers, APIs externas, serviços de e-mail, sistemas de arquivos. Todos esses são detalhes de implementação que mudam independentemente das suas regras de negócio. Abstraí-los por trás de uma interface isola seu domínio de mudanças e torna a troca de implementações (ex.: migrar de MySQL para MongoDB, ou de REST para gRPC) uma questão de escrever um novo adapter, em vez de reescrever seus use cases.
Quando o DIP pode ser excessivo é quando você está criando interfaces para colaboradores internos e estáveis que jamais terão mais de uma implementação. Se uma classe UserValidator não tem nenhuma implementação alternativa relevante e não é uma dependência externa, envolvê-la em uma interface apenas para “seguir o DIP” adiciona indireção sem benefício. O mesmo se aplica a classes utilitárias simples ou funções puras. Uma verificação mental útil: “Este é um detalhe que poderia mudar independentemente da minha lógica de negócio, ou que eu vou querer substituir por um fake nos testes?” Se a resposta for não, uma interface provavelmente é desnecessária.
A super-abstração é um risco real. Uma base de código onde cada classe tem uma interface correspondente — independentemente de a interface servir a algum propósito arquitetural — se torna mais difícil de navegar, não mais fácil. O objetivo do DIP é o desacoplamento controlado em fronteiras significativas, não a proliferação indiscriminada de interfaces. Aplique-o com intenção e ele trará dividendos. Aplique-o reflexivamente e ele se tornará ruído.
Conclusão
O Princípio da Inversão de Dependência é uma diretriz de design poderosa que muda fundamentalmente a forma como gerenciamos dependências no software. Ao garantir que tanto os módulos de alto nível quanto os de baixo nível dependam de abstrações, o DIP possibilita a criação de sistemas altamente desacoplados, flexíveis e testáveis.
Os principais aprendizados deste artigo são:
- O DIP é um princípio de design sobre a direção das dependências; a Injeção de Dependência é uma técnica para implementá-lo.
- Na Clean Architecture, a interface
UserRepositorypertence à camada de Domínio — de propriedade da política de alto nível, implementada pelo detalhe de baixo nível. Essa é a inversão. - O benefício prático é imediato: os use cases se tornam trivialmente testáveis ao trocar o adapter real por um stub em memória, sem banco de dados ou framework necessários.
- A conexão manual torna o mecanismo transparente; frameworks de DI como o Spring simplesmente o automatizam em larga escala.
- O DIP é mais valioso nas fronteiras voláteis (bancos de dados, APIs, serviços externos) e menos valioso quando aplicado reflexivamente a cada colaborador interno.
O DIP não existe sozinho — ele trabalha em conjunto com os outros princípios SOLID. O Princípio da Responsabilidade Única garante que cada classe tenha apenas um motivo para mudar, o que facilita a definição de fronteiras de abstração claras. O Princípio Aberto/Fechado é diretamente habilitado pelo DIP: como os módulos de alto nível dependem de abstrações, você pode estender o comportamento adicionando novas implementações sem modificar o código existente. O Princípio da Segregação de Interfaces mantém essas abstrações enxutas e focadas, prevenindo o tipo de interfaces inchadas que solapariam a intenção do DIP.
Tomados em conjunto, esses princípios guiam você em direção a uma arquitetura onde a lógica de negócio é protegida, a infraestrutura é substituível e o sistema como um todo é resiliente a mudanças. Adotar o DIP nas fronteiras certas é um passo significativo em direção à construção de software que permanece manutenível, testável e escalável ao longo de sua evolução.
Referências
[1] Martin, Robert C. “The Dependency Inversion Principle.” Object Mentor, http://www.objectmentor.com/resources/articles/dip.pdf.
[2] Martin, Robert C. “The Clean Architecture.” The Clean Code Blog, https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html.
[3] Fowler, Martin. “Inversion of Control Containers and the Dependency Injection pattern.” martinfowler.com, https://martinfowler.com/articles/injection.html.