1. Introduction
Recently, while working on a project, I encountered a race condition problem. This particular issue, often seen in high-concurrency scenarios like e-commerce (e.g., two users attempting to buy the last item simultaneously) or booking systems (e.g., overlapping property reservations), manifested when users attempted to add two records simultaneously, bypassing a check-before-insert validation.
Such validations, designed to prevent duplicates, can unexpectedly fail, especially when an application operates across multiple parallel pods or containers. When encountered for the first time, the inherent nature of these bugs can be subtle and confusing. They typically lead to symptoms like duplicate records or inconsistent data, and their non-deterministic behavior under heavy load and concurrency makes them notoriously challenging to reproduce and debug.
This highlights why understanding race conditions is critical in real systems, and why implementing robust strategies to effectively manage them in production environments is paramount.
2. What is a Race Condition?
A race condition occurs when the correctness of a program depends on the timing or interleaving of multiple concurrent operations. Essentially, it’s a flaw where the output of a system is unexpectedly affected by the sequence or timing of other uncontrollable events. This typically happens when multiple processes or threads access and modify shared resources without proper synchronization, leading to unpredictable and often incorrect results.
3. Simple Example
To illustrate the core concept of a race condition, particularly the ‘check-then-act’ pattern prevalent in scenarios like e-commerce inventory management or booking systems, consider a simplified example. Imagine a service designed to ensure a user has only one unique entry in a database. A seemingly logical, yet flawed, approach might involve checking for the entry’s existence and then, if absent, proceeding with the insertion:
public class UserService {
private Database database; // Assume this is a simplified database interface
public void createUserEntry(String userId) {
if (!database.userEntryExists(userId)) {
// Simulate some processing time
try { Thread.sleep(100); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
database.insertUserEntry(userId);
System.out.println("User entry for " + userId + " created.");
} else {
System.out.println("User entry for " + userId + " already exists.");
}
}
}
// In a concurrent environment:
// Thread A calls createUserEntry("user1")
// Thread B calls createUserEntry("user1")
In a concurrent environment, this ‘check-then-act’ sequence becomes problematic. If Thread A checks userEntryExists and finds no entry, and Thread B performs the same check before Thread A has completed its insertUserEntry operation, both threads will erroneously conclude that no entry exists. Consequently, both will proceed to insert the user entry, leading to duplicate records and violating the intended system state. This is analogous to two customers simultaneously checking for the last available product and both being told it’s in stock, only for one’s purchase to fail or for an oversell to occur.
4. Visualization Section
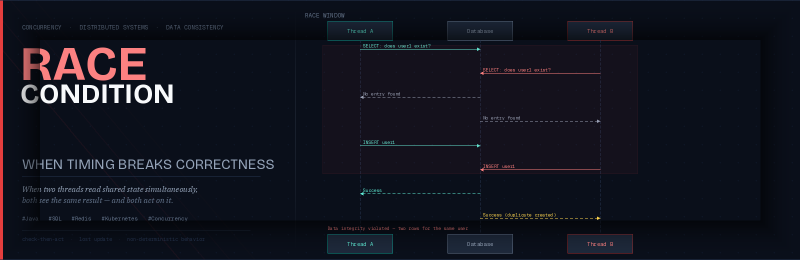
sequenceDiagram
participant A as Thread A (Request 1)
participant B as Thread B (Request 2)
participant DB as Database
A->>DB: SELECT: does user1 exist?
B->>DB: SELECT: does user1 exist?
DB-->>A: No entry found
DB-->>B: No entry found
Note over A,B: Both threads believe no entry exists
A->>DB: INSERT user1
B->>DB: INSERT user1
DB-->>A: ✅ Success
DB-->>B: ⚠️ Success (duplicate created)
Note over DB: Data integrity violated (no constraint)
This diagram illustrates two concurrent requests attempting to create a user entry. Both requests read the shared state (checking if the user exists) at roughly the same time, find no existing entry, and then both proceed to write (insert the user entry), leading to a race condition.
5. Why Race Conditions Happen
Race conditions are a common byproduct of modern software architectures, primarily due to:
- Concurrency: The simultaneous execution of multiple threads, processes, or distributed services that share resources. This is inherent in multi-threaded applications, web servers handling multiple requests, and microservices architectures.
- Lack of Synchronization: When access to shared resources (like database records, in-memory caches, or files) is not properly coordinated, allowing multiple operations to interfere with each other.
- Incorrect Assumption of Atomicity: Developers sometimes assume that a sequence of operations (e.g., read-modify-write) will execute as a single, indivisible unit, when in reality, they can be interrupted and interleaved by other operations.
Modern systems, especially those built with APIs and microservices, significantly increase the exposure to race conditions because of their distributed and highly concurrent nature.
6. Types of Race Conditions
Race conditions manifest in various forms, but the most critical often involve a ‘check-then-act’ pattern, where a decision is made based on a perceived state that can change before the action is completed. Two common and impactful types are:
6.1 Check-Then-Act Race Condition (e.g., Duplicate Inserts, Overselling Inventory, Overlapping Bookings)
This type of race condition is precisely what we discussed in the simple example. It occurs when multiple concurrent operations perform a check (e.g., “is this product in stock?” or “is this time slot available?”) and then, based on that check, proceed to act (e.g., “decrement stock” or “book time slot”). If the state changes between the check and the act due to another concurrent operation, the system can end up in an inconsistent state. This leads to issues like duplicate records, overselling inventory, or double-booking resources, which can have significant business implications.
6.2 Update Race Condition (Lost Update)
An update race condition, often referred to as a lost update, occurs when two or more concurrent operations attempt to modify the same piece of data, and one update overwrites another without incorporating its changes. For instance, if two users simultaneously try to update the quantity of an item in an inventory system, and both read the current quantity, perform a calculation, and then write the new quantity, one of the updates will be lost. While still a concern, these are often addressed differently with standard locking mechanisms compared to the ‘check-then-act’ scenarios where the initial check itself is vulnerable.
7. Strategies to Solve Race Conditions
There is no single, universal solution for all race conditions. The best approach depends on the specific context, the type of shared resource, and the performance requirements. Here are several effective strategies:
7.1 Database Constraints
For preventing insert race conditions and ensuring data integrity, database unique constraints are often the only reliable guarantee of correctness under concurrent writes. By defining a unique constraint on one or more columns, the database itself enforces data integrity at the most fundamental level. If a concurrent insert attempts to create a duplicate, the database will throw an error, which the application can then handle gracefully. It is a critical principle to remember: Application-level checks are not guarantees under concurrency.
ALTER TABLE user_entries ADD CONSTRAINT unique_user_id UNIQUE (user_id);
This approach shifts the responsibility of correctness to the database, which is highly optimized for such tasks. It is a fundamental truth in concurrent system design: In most systems, the database is the only layer that can reliably guarantee consistency under concurrent writes—everything else is best-effort.
7.2 Transactions + Locks (Check-Then-Insert with Locking)
For scenarios where database constraints alone are insufficient, or for more complex read-modify-write operations, database transactions combined with explicit locking can be used. It is crucial to understand that SELECT FOR UPDATE only locks existing rows. This approach does NOT prevent insert race conditions when the row does not exist; a unique constraint is still required. SELECT FOR UPDATE is effective for locking rows that are expected to exist and be modified. For example, in SQL databases, SELECT FOR UPDATE can be used to acquire an exclusive lock on an existing row (or rows) before performing an update, ensuring that no other transaction can modify or lock that row until the current transaction commits or rolls back.
-- Transaction 1: Locking an existing row for update
BEGIN;
SELECT * FROM products WHERE id = 123 FOR UPDATE;
UPDATE products SET quantity = quantity - 1 WHERE id = 123;
COMMIT;
-- Transaction 2 (will wait for Transaction 1 to commit or rollback if it tries to acquire the same lock on product id 123)
This ensures that only one transaction can operate on the locked data at a time, providing mutual exclusion and preventing race conditions on existing records. It’s important to note that while transactions provide atomicity (all or nothing), locks (e.g., SELECT FOR UPDATE) provide mutual exclusion and coordination. Proper isolation levels and/or explicit locking mechanisms are required to achieve full concurrency control and prevent race conditions.
7.2.1 Transaction Isolation Levels
Database transaction isolation levels play a critical role in how race conditions are handled. READ COMMITTED isolation, the default for many databases, does not prevent race conditions like lost updates or non-repeatable reads. REPEATABLE READ offers stronger guarantees, preventing non-repeatable reads but still allowing for insert race conditions (phantom reads) as defined by the SQL standard. The highest isolation level, SERIALIZABLE, effectively prevents all race conditions by ensuring transactions execute as if they were run sequentially, but this comes with a significant performance impact due to increased locking and contention.
Note: PostgreSQL’s implementation of
REPEATABLE READis stronger than the SQL standard requires. Because it uses snapshot isolation rather than range locks, it also prevents phantom reads in practice — behavior that the standard only guarantees atSERIALIZABLE. If you are working exclusively with PostgreSQL,REPEATABLE READmay be sufficient for scenarios where other databases would requireSERIALIZABLE.
7.3 UPSERT (INSERT … ON CONFLICT / ON DUPLICATE KEY)
UPSERT (a portmanteau of “UPDATE” and “INSERT”) is a common and highly effective real-world solution for preventing duplicate inserts and handling concurrent updates, especially when a unique constraint is present. This pattern allows an application to attempt an insert, and if a conflict arises due to an existing unique key, it can either do nothing or update the existing row instead. This relies directly on the database’s ability to handle the conflict atomically, making it simpler and safer than application-level check-then-act logic.
PostgreSQL Example:
INSERT INTO user_entries (user_id)
VALUES ('user1')
ON CONFLICT (user_id) DO NOTHING;
MySQL Example:
INSERT INTO user_entries (user_id)
VALUES ('user1')
ON DUPLICATE KEY UPDATE user_id = user_id;
UPSERT operations are inherently idempotent when combined with a unique constraint, as they ensure that repeated executions lead to the same final state. This pattern is often the preferred way to handle “check-then-act” scenarios for inserts when a unique constraint is defined.
7.4 Pessimistic Locking
Pessimistic locking assumes that conflicts are likely and prevents them by acquiring a lock on a resource before accessing it. This means that other operations attempting to access the same resource will be blocked until the lock is released. While effective in preventing race conditions, it can lead to reduced concurrency and potential deadlocks if not managed carefully.
- Pros: Guarantees data consistency, relatively straightforward to implement for critical sections.
- Cons: Can significantly reduce system throughput, increases the risk of deadlocks, and can be complex to manage in distributed systems. To mitigate deadlocks, always acquire locks in a consistent order across transactions and utilize lock timeouts to prevent indefinite blocking.
7.5 Optimistic Locking
In contrast to pessimistic locking, optimistic locking assumes that conflicts are rare. Instead of locking resources upfront, it allows multiple operations to proceed concurrently. When an operation attempts to commit its changes, it checks if the resource has been modified by another concurrent operation since it was initially read. This is typically achieved using a version number or a timestamp column. Crucially, this version check should ideally be enforced at the database level to provide a true guarantee.
This pattern often involves a conditional update at the database level:
UPDATE product
SET quantity = ?, version = version + 1
WHERE id = ? AND version = ?;
After executing such an UPDATE statement, the application checks the number of affected rows. If exactly one row was affected, the update was successful. If zero rows were affected, it indicates that another transaction modified the record concurrently (i.e., the version in the WHERE clause no longer matched), and a conflict was detected. In this case, the operation is typically rolled back, and the client is instructed to retry. This approach offers higher concurrency but requires implementing retry logic on the client side.
- Pros: High concurrency, avoids deadlocks.
- Cons: Requires retry mechanisms, conflicts can lead to wasted work if retries are frequent.
7.6 Idempotency Keys
Idempotency keys are a powerful mechanism, particularly useful in API design and distributed systems, primarily to prevent duplicate processing of requests (e.g., due to client-side retries or network issues). An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application. By including a unique idempotency key with each request, the server can detect and ignore subsequent requests with the same key, ensuring that an operation (e.g., charging a customer, creating a resource) is performed only once. Idempotency keys are typically enforced using a unique constraint at the database level. It is crucial to understand that while idempotency keys prevent duplicate requests from causing duplicate effects, they do not inherently replace proper concurrency control mechanisms for managing shared state. They address the problem of duplicate message delivery, not concurrent access to a shared resource.
7.7 Distributed Locks (Advanced)
In distributed systems, where multiple services or instances might be trying to access the same shared resource, traditional in-process locks are insufficient. Distributed locks are used to coordinate access across different processes or machines. Tools like Redis or Apache ZooKeeper can be used to implement distributed locking mechanisms.
For simple, single-node Redis instances, a basic distributed lock can be implemented using the SET key value NX PX milliseconds command. This command sets a key only if it doesn’t already exist (NX) and sets an expiration time (PX), providing a basic mutual exclusion mechanism. However, this approach is vulnerable if the Redis instance fails.
For multi-node Redis deployments (e.g., Redis Sentinel or Cluster), algorithms like Redlock were proposed to achieve more robust distributed locks. However, it is crucial to note that Redis-based distributed locks, such as Redlock, are controversial and must be used with extreme caution. Distributed locks should never be the only line of defense for data consistency; correctness must still be guaranteed at the database level. They introduce significant complexity and their correctness guarantees under various failure scenarios are debated within the engineering community [1][2]. Implementing distributed locks is significantly more complex and introduces its own set of challenges, including network latency, fault tolerance, and ensuring consistency.
- Warning: Distributed locks add significant complexity and should only be considered when simpler solutions are not viable for distributed environments. Be particularly wary of solutions like Redlock without a deep understanding of their limitations and trade-offs.
8. Choosing the Right Approach
Selecting the appropriate strategy for dealing with race conditions involves understanding the trade-offs between consistency, performance, and complexity.
A good rule of thumb is: whenever possible, push correctness guarantees down to the database layer instead of relying on application-level coordination.
- Check-Then-Act Race Conditions (e.g., Duplicate Inserts, Overselling, Overlapping Bookings): For these critical scenarios, database unique constraints are the primary and most reliable solution for preventing duplicate inserts. When dealing with complex state changes or resource allocation, robust mechanisms like transactions with
SELECT FOR UPDATE(pessimistic locking) or carefully implemented distributed locks are often necessary to guarantee atomicity and prevent race conditions. The choice here hinges on the specific consistency requirements, the nature of the shared resource, and the acceptable trade-offs in performance and complexity. - Update Race Conditions (Lost Updates): For preventing lost updates, optimistic locking is generally the preferred approach due to its higher concurrency, especially in web applications where multiple users might concurrently edit data. It effectively handles conflicts by requiring client-side retry logic.
- Critical Sections (requiring strict mutual exclusion): When absolute data consistency is paramount for a short, well-defined critical section, pessimistic locking (e.g.,
SELECT FOR UPDATEon existing records) can be employed. However, one must be acutely aware of its impact on system throughput and the increased risk of deadlocks.
Always consider the specific requirements of your system and the potential impact of each solution on performance and maintainability.
9. Lessons Learned (Personal Insight)
My encounters with race conditions have taught me several invaluable lessons:
- Race conditions are subtle and hard to reproduce: They often manifest under specific load conditions or rare timing sequences, making them notoriously difficult to debug in development environments.
- If correctness depends on timing, your system is relying on luck. Any code that relies on the precise order or speed of execution of concurrent operations is a prime candidate for a race condition. Always question assumptions about timing.
- Prefer guarantees over assumptions: Instead of assuming operations are atomic or that external factors will always align, build systems that provide explicit guarantees of correctness, whether through database constraints, locking mechanisms, or idempotent operations.
- Avoid relying on a single layer for validation (when possible): When your system uses strong guarantees at a lower layer (such as database constraints), it is often beneficial to complement them with application-level validation (e.g., a check-before-insert). This additional check does not provide correctness under concurrency, but it can reduce unnecessary database operations and, more importantly, improve user experience by failing fast and providing clearer feedback. In practice, the lower layer enforces correctness, while the application layer optimizes for usability and efficiency.
10. Conclusion
Race conditions are an inherent challenge in concurrent and distributed systems. While they can be elusive and frustrating to debug, understanding their causes and knowing the various strategies to mitigate them is crucial for building robust and reliable software. By enforcing correctness at the right layer—often the database—and carefully choosing synchronization mechanisms, software engineers can effectively deal with race conditions and ensure the integrity of their systems.
11. Optional: Testing Race Conditions
Testing for race conditions is inherently difficult due to their non-deterministic nature. However, several strategies can help uncover them:
- Parallel Requests: Simulate multiple concurrent requests to the same endpoint or resource. Tools like Apache JMeter or custom scripts can be used to flood the system with simultaneous operations.
- Load Testing: Subjecting the system to high load can increase the probability of race conditions manifesting. This helps identify bottlenecks and areas where concurrency issues might arise.
- Chaos Engineering: Intentionally introducing latency or failures in a controlled environment can sometimes expose timing-dependent bugs that lead to race conditions.
While challenging, incorporating these testing strategies into your development workflow can significantly improve the resilience of your applications against race conditions.
12. References
[1] Kleppmann, M. (2016, February 8). How to do distributed locking. https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
[2] Antirez. (2016, February 9). Is Redlock safe? https://antirez.com/news/101