In the pursuit of building robust, maintainable, and testable software systems, architectural principles play a pivotal role. Among these, the Dependency Inversion Principle (DIP) stands out as a cornerstone for achieving highly decoupled and flexible designs, especially when applied within frameworks like Clean Architecture. This post will explore the Dependency Inversion Principle, clarify its relationship with Dependency Injection, and demonstrate its practical application in Java, particularly in decoupling the Domain and Infrastructure layers.
Understanding the Dependency Inversion Principle (DIP)
The Dependency Inversion Principle, one of the five SOLID principles of object-oriented design, was articulated by Robert C. Martin (Uncle Bob). It consists of two core statements [1]:
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
In essence, DIP advocates for designing software such that modules depend on abstractions (interfaces or abstract classes) rather than concrete implementations. This principle ensures that high-level policies and business logic remain independent of the low-level details of their implementation. This inversion of the dependency direction is fundamental to creating flexible and resilient software systems.
DIP vs. Dependency Injection (DI)
It’s common to confuse DIP with Dependency Injection (DI), but they are distinct concepts:
- Dependency Inversion Principle (DIP) is a design principle. It’s about the direction of dependencies, stating that high-level modules should not depend on low-level modules, but rather on abstractions. It’s a high-level architectural guideline, focusing on what to achieve in terms of dependency direction [2].
- Dependency Injection (DI) is a design pattern and a technique for implementing DIP. It’s about how dependencies are provided to a class. Instead of a class creating its own dependencies, they are injected into it from an external source (often a DI container). DI is a concrete mechanism for how to achieve the inversion of control prescribed by DIP [3].
In simpler terms, DIP is the strategy for decoupling, and DI is one of the tactics to execute that strategy.
The Dependency Inversion Principle in Clean Architecture
graph TD
subgraph DomainLayer ["🏛️ Domain Layer"]
direction TB
U["👤 UserEntity"]
URI["📋 UserRepository<br/>«interface»"]
end
subgraph ApplicationLayer ["🎯 Application Layer"]
direction TB
UC["🔧 CreateUserUseCase<br/><span style="white-space: nowrap;">Orchestrates domain objects"</span>]
end
subgraph InfrastructureLayer ["🔌 Infrastructure Layer"]
direction TB
URA["<span style="white-space: nowrap;">🗄️ JpaUserRepositoryAdapter</span><br/>implements UserRepository"]
DB[("💾 DatabasePostgreSQL / MySQL")]
end
subgraph CompositionRoot ["🧩 Composition Root"]
direction TB
DI["⚡ DI Container<br/>Spring / <span style="white-space: nowrap;">Guice</span> / Manual"]
end
%% Core dependency arrows
UC -->|"depends on (compile-time)"| URI
URA -.->|"<span style="white-space: nowrap;">implements (runtime binding)</span>"| URI
%% Domain internal relationships
UC -->|uses| U
URA -->|maps to/from| U
URA -->|persists via| DB
%% DI Container wires the adapter into the use case
DI -->|"<span style="white-space: nowrap;">injects adapter into use case</span>"| UC
%% Styling — refined, editorial palette
classDef domain fill:#1e1b4b,color:#e0e7ff,stroke:#6366f1,stroke-width:2px
classDef application fill:#14532d,color:#dcfce7,stroke:#22c55e,stroke-width:2px
classDef infra fill:#1c1917,color:#fef3c7,stroke:#f59e0b,stroke-width:2px
classDef composition fill:#1e293b,color:#e2e8f0,stroke:#94a3b8,stroke-width:2px,stroke-dasharray:6 3
class U,URI domain
class UC application
class URA,DB infra
class DI composition
style DomainLayer fill:#0f0e2a,color:#a5b4fc,stroke:#6366f1,stroke-width:3px
style ApplicationLayer fill:#052e16,color:#86efac,stroke:#22c55e,stroke-width:3px
style InfrastructureLayer fill:#0c0a09,color:#fde68a,stroke:#f59e0b,stroke-width:3px
style CompositionRoot fill:#0f172a,color:#cbd5e1,stroke:#64748b,stroke-width:2px,stroke-dasharray:8 4
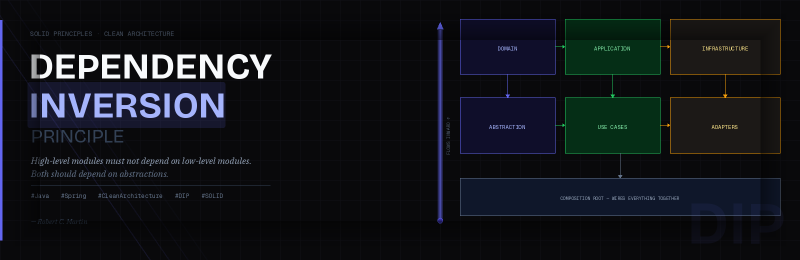
Clean Architecture, as advocated by Robert C. Martin, structures applications into concentric layers, with the core business logic (the Domain layer) at the center. A fundamental rule of Clean Architecture is the Dependency Rule: source code dependencies must always point inwards, towards the higher-level policies and business rules. No outer layer should ever affect an inner layer [2].
This is precisely where DIP becomes indispensable. Without DIP, the Application Layer (which contains Use Cases, representing high-level policies) would naturally depend on the Infrastructure Layer (low-level details) for things like database access or external service calls. For instance, a CreateUserUseCase might directly call a JpaUserRepository.
DIP solves this by inverting the dependency. Instead of the Application Layer depending on the Infrastructure Layer, both layers depend on an abstraction defined within the Domain Layer itself. The Infrastructure Layer then implements this abstraction.
Consider the typical flow:
- Application Layer (e.g., Use Cases) depends on interfaces (abstractions) defined in the Domain Layer.
- Domain Layer defines core business entities, value objects, domain services, and interfaces (abstractions) for external concerns like data persistence.
- Infrastructure Layer (e.g., concrete repositories) implements these interfaces defined in the Domain Layer.
- At runtime, an external mechanism (often a Dependency Injection framework) provides the Application Layer with instances of the Infrastructure Layer’s implementations, but only through their abstract interfaces.
This means the source code dependency flows from the Infrastructure Layer towards the Domain Layer (because the Infrastructure Layer implements an interface defined in the Domain), while the Application Layer depends on the Domain Layer. The flow of control (at runtime) goes from the Application Layer, through the Domain Layer’s abstractions, to the Infrastructure Layer’s implementations. This inversion is key to preserving the independence of the core business logic and use cases.
Practical Example in Java
Let’s illustrate how DIP is applied in a Java application following Clean Architecture principles, using a User entity, a UserRepository for data persistence, and a CreateUserUseCase.
1. Domain Layer: Defining the Abstraction (Core Business Logic)
The Domain layer contains the core business logic, defining the User entity and the UserRepository interface. This interface is the abstraction that the CreateUserUseCase (in the Application Layer) will depend on. By placing the interface here, the Domain layer remains completely unaware of how user data is actually persisted.
// domain/model/User.java
package com.example.cleanarch.domain.model;
public class User {
private String id;
private String name;
private String email;
public User(String id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
// Getters and setters
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
}
// domain/port/UserRepository.java (Abstraction/Port)
package com.example.cleanarch.domain.port;
import com.example.cleanarch.domain.model.User;
import java.util.Optional;
public interface UserRepository {
User save(User user);
Optional<User> findById(String id);
}
2. Application Layer: Defining Use Cases (High-Level Policy)
The Application layer contains the application-specific business rules and orchestrates the flow of data to and from the Domain layer. Here, the CreateUserUseCase depends on the UserRepository interface defined in the Domain layer.
// application/usecase/CreateUserUseCase.java (High-Level Module)
package com.example.cleanarch.application.usecase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
public class CreateUserUseCase {
private final UserRepository userRepository;
public CreateUserUseCase(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User execute(User user) {
// Application-specific business logic can go here before saving
// e.g., validation, logging, event publishing
return userRepository.save(user);
}
}
3. Infrastructure Layer: Implementing the Abstraction (Low-Level Detail)
The Infrastructure layer contains the concrete details, such as database access. Here, we implement the UserRepository interface defined in the Domain layer. This implementation might use a specific database framework like Spring Data JPA, Hibernate, or a NoSQL client.
// infrastructure/adapter/JpaUserRepositoryAdapter.java (Detail/Adapter)
package com.example.cleanarch.infrastructure.adapter;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository // Example with Spring Framework
public class JpaUserRepositoryAdapter implements UserRepository {
// Assume a Spring Data JPA repository for actual DB operations
private final SpringDataJpaUserRepository springDataJpaUserRepository;
public JpaUserRepositoryAdapter(SpringDataJpaUserRepository springDataJpaUserRepository) {
this.springDataJpaUserRepository = springDataJpaUserRepository;
}
@Override
public User save(User user) {
// Convert domain User to JPA entity if necessary
// Save using springDataJpaUserRepository
System.out.println("Saving user to database: " + user.getName());
return user; // For simplicity, returning the same user
}
@Override
public Optional<User> findById(String id) {
// Find using springDataJpaUserRepository and convert to domain User
System.out.println("Finding user by ID: " + id);
return Optional.of(new User(id, "Test User", "test@example.com")); // Mock for simplicity
}
}
// Dummy Spring Data JPA Repository (would be in infrastructure/repository)
interface SpringDataJpaUserRepository {
// UserEntity save(UserEntity userEntity);
// Optional<UserEntity> findById(String id);
}
Notice that JpaUserRepositoryAdapter depends on UserRepository (an abstraction in the Domain layer). This is the inversion: the low-level module now depends on the high-level abstraction, not the other way around.
4. Composition Root: Wiring Dependencies
In the Composition Root (often part of the Application Layer or a dedicated configuration module), the concrete JpaUserRepositoryAdapter is provided to the CreateUserUseCase. This is typically done using a Dependency Injection framework (like Spring, Guice, or Dagger), which automates the process of creating instances and injecting them through the UserRepository interface.
// application/config/AppConfig.java (Composition Root Example with Spring)
package com.example.cleanarch.application.config;
import com.example.cleanarch.application.usecase.CreateUserUseCase;
import com.example.cleanarch.domain.port.UserRepository;
import com.example.cleanarch.infrastructure.adapter.JpaUserRepositoryAdapter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public UserRepository userRepository() {
// In a real app, this would involve creating and configuring
// the actual SpringDataJpaUserRepository or similar.
// For this example, we'll pass a null or mock for simplicity.
return new JpaUserRepositoryAdapter(null); // Actual Spring Data JPA repo would be injected here by Spring
}
@Bean
public CreateUserUseCase createUserUseCase(UserRepository userRepository) {
return new CreateUserUseCase(userRepository);
}
// Example of how to use it (e.g., in a main method or controller)
public static void main(String[] args) {
// This part is typically handled by the Spring Application Context
// For demonstration:
UserRepository repo = new JpaUserRepositoryAdapter(null);
CreateUserUseCase useCase = new CreateUserUseCase(repo);
User newUser = new User("1", "John Doe", "john.doe@example.com");
useCase.execute(newUser);
}
}
At runtime, the CreateUserUseCase receives an instance of JpaUserRepositoryAdapter through its UserRepository interface. The Application and Domain layers remain oblivious to the concrete implementation, adhering strictly to DIP.
Manual Wiring (Without a Framework)
It’s worth understanding what a DI framework does under the hood. Here is the equivalent wiring done entirely by hand — no Spring, no Guice, just plain Java:
// main/Main.java (Manual Composition Root)
package com.example.cleanarch.main;
import com.example.cleanarch.application.usecase.CreateUserUseCase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import com.example.cleanarch.infrastructure.adapter.JpaUserRepositoryAdapter;
public class Main {
public static void main(String[] args) {
// 1. Create the low-level detail (the concrete adapter)
UserRepository repository = new JpaUserRepositoryAdapter(null);
// 2. Inject it into the high-level use case through the interface
CreateUserUseCase createUser = new CreateUserUseCase(repository);
// 3. Execute — CreateUserUseCase has no idea it's talking to JPA
User newUser = new User("1", "John Doe", "john.doe@example.com");
createUser.execute(newUser);
}
}
This is the essence of DIP in action. CreateUserUseCase is constructed with a UserRepository reference and never knows — or cares — that the concrete type behind it is JpaUserRepositoryAdapter. A framework like Spring simply automates this wiring at scale by scanning @Bean or @Component annotations and building the entire object graph for you. The principle is identical; the framework just removes the boilerplate.
Testing with DIP: Mocking the Repository
One of the most immediate and tangible payoffs of DIP is how dramatically it simplifies unit testing. Because CreateUserUseCase depends on the UserRepository interface rather than a concrete JPA class, you can substitute a lightweight in-memory mock during tests — no database, no Spring context, no slow I/O.
// application/usecase/CreateUserUseCaseTest.java
package com.example.cleanarch.application.usecase;
import com.example.cleanarch.domain.model.User;
import com.example.cleanarch.domain.port.UserRepository;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import static org.junit.jupiter.api.Assertions.*;
class CreateUserUseCaseTest {
// A simple in-memory stub — no Mockito, no Spring, no database needed
static class InMemoryUserRepository implements UserRepository {
private final List<User> store = new ArrayList<>();
@Override
public User save(User user) {
store.add(user);
return user;
}
@Override
public Optional<User> findById(String id) {
return store.stream().filter(u -> u.getId().equals(id)).findFirst();
}
public List<User> getStore() { return store; }
}
@Test
void shouldSaveUserSuccessfully() {
// Arrange: inject the in-memory stub through the interface
InMemoryUserRepository fakeRepo = new InMemoryUserRepository();
CreateUserUseCase useCase = new CreateUserUseCase(fakeRepo);
User user = new User("1", "John Doe", "john.doe@example.com");
// Act
User result = useCase.execute(user);
// Assert: pure business logic verified, zero infrastructure involved
assertNotNull(result);
assertEquals("John Doe", result.getName());
assertEquals(1, fakeRepo.getStore().size());
}
}
Because the UserRepository abstraction lives in the Domain layer, the test imports nothing from the Infrastructure layer. Swapping JpaUserRepositoryAdapter for InMemoryUserRepository is trivial — you simply pass a different implementation to the constructor. This is the DIP payoff: your business logic is fully testable in isolation, with no need for a running database or a loaded Spring context.
Benefits of the Dependency Inversion Principle
Applying DIP, especially within Clean Architecture, brings numerous advantages:
- Enhanced Decoupling: High-level modules (Application Layer Use Cases) are completely independent of low-level implementation details (Infrastructure Layer). This means changes in the database technology or external services do not necessitate changes in the core business logic or application flows.
- Improved Testability: Since high-level modules depend on abstractions defined in the Domain Layer, it’s straightforward to provide mock or stub implementations of these abstractions during unit testing. This allows for isolated testing of business logic and use cases without external dependencies.
- Increased Flexibility and Maintainability: The system becomes more adaptable to change. New implementations of an abstraction can be introduced without altering the high-level modules. This simplifies maintenance and allows for easier evolution of the system.
- Promotes Reusability: Core business logic and application use cases, being free from infrastructure concerns, can be reused across different applications or deployment contexts.
- Clearer Architecture: DIP enforces clear boundaries between layers, making the architecture easier to understand and reason about.
Real-World Trade-offs: When DIP Shines and When It Doesn’t
DIP is a powerful tool, but like any design principle, applying it indiscriminately can introduce unnecessary complexity. Understanding where it adds the most value — and where it may be overkill — is key to using it wisely.
When DIP is most valuable is precisely at the boundaries between your core business logic and volatile, external concerns: databases, message brokers, external APIs, email services, file systems. These are all implementation details that change independently of your business rules. Abstracting them behind an interface insulates your domain from churn and makes swapping implementations (e.g., migrating from MySQL to MongoDB, or from REST to gRPC) a matter of writing a new adapter rather than rewriting your use cases.
When DIP may be overkill is when you’re creating interfaces for internal, stable collaborators that will never have more than one implementation. If a UserValidator class has no meaningful alternative implementation and is not an external dependency, wrapping it in an interface just to “follow DIP” adds indirection without benefit. The same applies to simple utility classes or pure functions. A useful mental check: “Is this a detail that could change independently of my business logic, or that I’ll want to replace with a fake in tests?” If the answer is no, an interface is likely unnecessary.
Over-abstraction is a real risk. A codebase where every single class has a corresponding interface — regardless of whether the interface serves any architectural purpose — becomes harder to navigate, not easier. The goal of DIP is controlled decoupling at meaningful boundaries, not blanket interface proliferation. Apply it with intention, and it pays dividends. Apply it reflexively, and it becomes noise.
Conclusion
The Dependency Inversion Principle is a powerful design guideline that fundamentally shifts how we manage dependencies in software. By ensuring that both high-level and low-level modules depend on abstractions, DIP enables the creation of highly decoupled, flexible, and testable systems.
The key takeaways from this article are:
- DIP is a design principle about the direction of dependencies; Dependency Injection is a technique for implementing it.
- In Clean Architecture, the
UserRepositoryinterface belongs in the Domain layer — owned by the high-level policy, implemented by the low-level detail. This is the inversion. - The practical payoff is immediate: use cases become trivially testable by swapping the real adapter for an in-memory stub, with no database or framework required.
- Manual wiring makes the mechanism transparent; DI frameworks like Spring simply automate it at scale.
- DIP is most valuable at volatile boundaries (databases, APIs, external services) and least valuable when applied reflexively to every internal collaborator.
DIP does not stand alone — it works in concert with the other SOLID principles. The Single Responsibility Principle ensures each class has one reason to change, which makes it easier to define clean abstraction boundaries in the first place. The Open/Closed Principle is directly enabled by DIP: because high-level modules depend on abstractions, you can extend behavior by adding new implementations without modifying existing code. The Interface Segregation Principle keeps those abstractions lean and focused, preventing the kind of bloated interfaces that would undermine DIP’s intent.
Taken together, these principles guide you toward an architecture where business logic is protected, infrastructure is replaceable, and the system as a whole is resilient to change. Embracing DIP at the right boundaries is a significant step towards building software that remains maintainable, testable, and scalable as it evolves.
References
[1] Martin, Robert C. “The Dependency Inversion Principle.” Object Mentor, http://www.objectmentor.com/resources/articles/dip.pdf.
[2] Martin, Robert C. “The Clean Architecture.” The Clean Code Blog, https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html.
[3] Fowler, Martin. “Inversion of Control Containers and the Dependency Injection pattern.” martinfowler.com, https://martinfowler.com/articles/injection.html.